
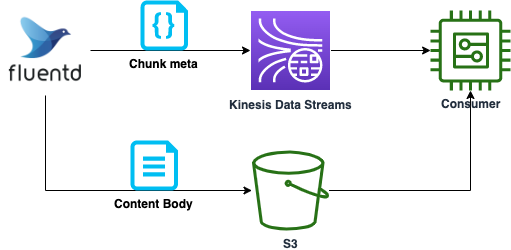
Kinesis Data Streams には、1 レコードのサイズは 1MB 以下でなければならない制約があり、サイズの大きいデータを転送するには工夫が必要となります。また利用料金はストリームに読み書きされるデータ量に基づいて決定されるため、サイズが大きいと課金額も増えてしまいます。本記事では Publisher が Fluentd の場合において、上記課題を解決する方法についてご紹介します。メッセージをメタデータと本体に分割し、本体は S3 経由で Consumer に渡し、メタデータのみを Kinesis Data Streams へ送ることで実現します。
Kinesis Data Streams について
Kinesis Data Streams (以降 KDS と呼称) は、フルマネージドのサーバレスストリーミングサービスです。シンプルな従量制課金を採用しており、シャードの稼働時間に応じて料金は計算されます。シャードは基本的なスループットの単位であり、スループット要件に応じて必要なシャード数を決定します。なおオンデマンドモードを利用した場合、読み書きのデータ量に応じて自動的にシャード数のスケールが行われます。詳細はAmazon Kinesis Data Streams の料金をご覧ください。
また KDS では 1 レコードのサイズが 1MB 以下である必要があります。詳細はQuotas and Limitsをご確認ください。
方針
各レコードにユニークな ID を割り当て、KDS では ID のみを、S3 バケットへはレコードの本体をそれぞれ送信します。バケットのオブジェクトキーに ID を含ませておけば、Consumer 側で ID を元にバケットから本体のデータを取得し処理することができます。これにより KDS で取り扱うレコードのサイズを削減することが可能です。本記事では、Fluentd を用いた場合について具体的に解説します。
想定するレコード例
サイズの大きなレコードの例を示します。
[
{
"metrics_name": "metrics1",
"metrics_value": 24.1,
...
},
{
"metrics_name": "metrics2",
"metrics_value": 312.56,
...
},
...以降続く
]
上記の配列を「1 レコード」として取り扱うことを想定しています。この例の場合、各metricsを別々のレコードとして取り扱えばサイズを 1MB に抑えることも可能でしょう。しかし Fluentd の入力側の都合や (技術的な課題や組織的な事情)、個々のmetrics間に依存関係があるため Consumer 側ではまとめて処理した方が見通しが良い等の事情により、分割することが困難または妥当でないケースがあります。また上記の配列単位で順序性が担保されれば良い場合、KDS にすべて送信すると前述のコスト体系により予算面で厳しいケースも考えれます。このような課題を前述の方針により解決を図ります。
Fluentd のバッファリング
Fluentd ではレコードをバッファリングし、まとめて送信する機能があります。これによりログの欠損防止や流量の制御が可能です。本記事ではバッファリングの利用を前提とします。
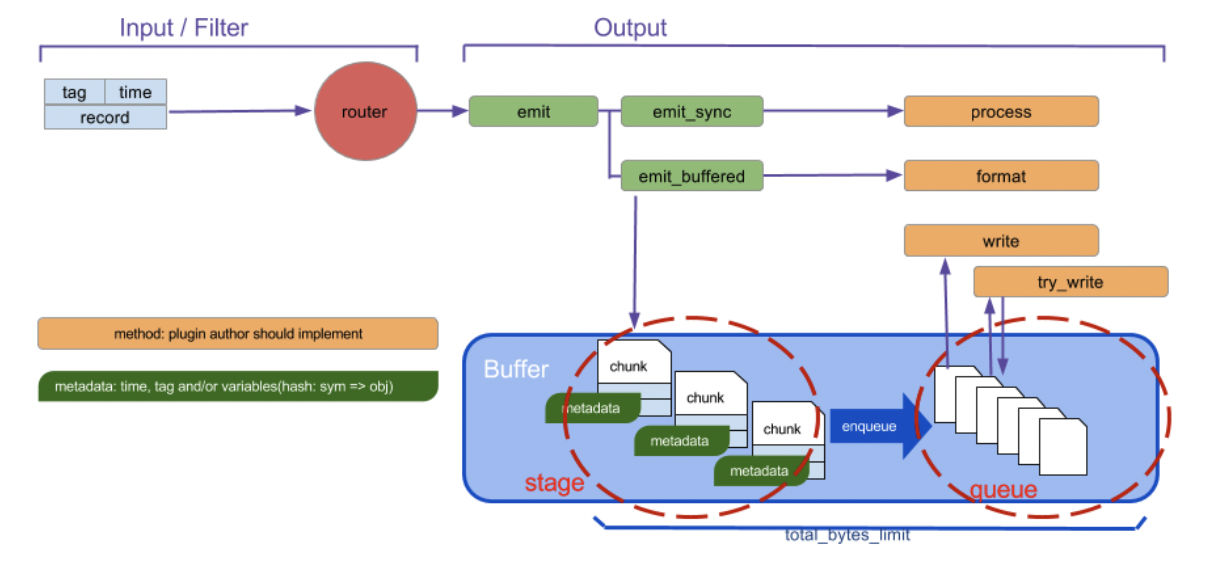
Fluentd のバッファの仕組みを下記に示します。
 引用先
引用先
バッファリングには stage と queue の 2 ステップが存在します。stage の段階でイベントの塊であるチャンク (chunk) を作成し、時間経過とともにエンキューされ、Output Plugin の指定する宛先へ送信されます。なおイベントはレコード (送信したいデータ本体)、タグ、タイムスタンプの 3 つの要素から構成されます。タグは Fluentd の備える主要な要素であり、Fluentd の内部でのルーティングに利用されます。Fluentd へデータを投入する Input Plugin はレコードにタグをつけ、Fluentd はそのタグにマッチするmatchディレクティブを検索し、対応する Output Plugin へルーティングします。
たとえば下記のような 2 つのダミーのデータソースがあるとします。それぞれタグはexample.hello, example.hogeです。
<source>
@type dummy
dummy {"hello": "world"}
tag example.hello
</source>
<source>
@type dummy
dummy {"hoge": "hoge"}
tag example.hoge
</source>
上記両方ともにexample_bucketという名前の S3 バケットへ転送したい場合、対応する match ディレクティブは下記のようになります。
<match example.**>
@type s3
s3_bucket example_bucket
</match>
それぞれ別のバケット (hello_bucket, hoge_bucket)へ転送したい場合は下記のように記述します。
<match example.hello>
@type s3
s3_bucket hello_bucket
</match>
<match example.hoge>
@type s3
s3_bucket hoge_bucket
</match>
詳細はConfig File Syntaxをご覧ください。
チャンク
チャンクを作成するとき、Chunk keyと呼ばれるキーを指定しグルーピングすることができます。キーにはタグの他、タイムキーなどを含めることができます。
例えば下記のように記述した場合、イベントは 60 秒ごと、かつタグごとにグルーピングされチャンクが作られます。
<buffer time, tag>
timekey 60
</buffer>
チャンクを S3 へ転送する際、上記のチャンクに付与されたユニークな ID を KDS へ転送すれば Consumer 側で S3 のオブジェクトを取得できます。ユニークな ID は Output Plugin のchunk.unique_id、Chunk key で利用したタグやタイムキーはchunk.metadataから取得することが可能です。
Fluentd 自身のログをキャプチャする
チャンクのユニークな ID を KDS へ転送するには、Fluentd への入力としてchunk.unique_idおよびchunk.metadataを与える必要があります。ここでは Fluentd 自身のログをキャプチャする方法を利用します。
Fluentd は Fluentd 自身のログをfluentタグをつけて管理しています。このログは<label @FLUENT_LOG>内でmatchディレクティブを記載することで処理できます。たとえば下記のように記載すると、すべてのログレベルのログを KDS へ転送します。
<label @FLUENT_LOG>
<match fluent.*>
@type kinesis_streams
...
</match>
</label>
Fluentd の S3 Output プラグインでは S3 転送時にchunk.unique_idおよびchunk.metadataを含んだログをdebug レベルで出力します。下記ログをキャプチャし KDS へ転送すれば、Consumer 側で S3 のオブジェクトキーを特定できます。
log.debug "out_s3: write chunk #{dump_unique_id_hex(chunk.unique_id)} with metadata #{chunk.metadata} to s3://#{@s3_bucket}/#{s3path}"
Fluentd のコンフィギュレーション
以上の内容を踏まえ、S3 へ本体を転送し、 KDS へメタデータを送るコンフィギュレーション例を作成してみます。
ログレベルの設定
S3 Output プラグインは 前述のチャンク情報を含むログを debug レベルで出力するため、systemセクションに下記のように設定します。参考
<system>
log_level debug
<log>
format json
time_format %Y-%m-%d
</log>
</system>
S3
ここでは後にAmazon Athenaを用い効率的にクエリできるよう、Hive 形式 (s3://year=yyyy/month=mm/day=dd) かつ gzip に圧縮し出力するものとします。
下記のように設定すると、S3 バケットへはs3://example_bucket/log/year=2023/month=01/day=05/{チャンクID}.gzipのような形式で保存されます。
<match example.log>
@type s3
s3_bucket example_bucket
s3_object_key_format ${tag[1]}/%{time_slice}/${chunk_id}.%{file_extension}
store_as gzip
time_slice_format year=%Y/month=%m/day=%d
<format>
@type json
</format>
<buffer time,tag>
timekey 10s
</buffer>
</match>
S3 に保存されるデータ例を下記に示します。上記の設定の場合 10 秒の間に到達した想定するレコードを json フォーマットで並べたものになります。
{
[
{
"metrics_name": "metrics1",
"metrics_value": 24.1
},
{
"metrics_name": "metrics2",
"metrics_value": 312.56
},
...
]
}
{
[
{
"metrics_name": "metrics1",
"metrics_value": 28.1
},
{
"metrics_name": "metrics2",
"metrics_value": 356.13
},
...
]
}
...
Fluentd 自身のログのフィルタリング
Fluentd のFilter Pluginsを使うと、送信したい内容を抽出・加工することができます。
まず前述した S3 Output プラグインが S3 転送した時のログを下記の設定により抽出します。
<filter fluent.debug>
@type grep
<regexp>
key message
pattern /out_s3: write chunk/
</regexp>
</filter>
これにより例えば下記のようなログのみが抽出できます。
{
"time": "2023-01-06",
"level": "debug",
"message": "out_s3: write chunk 5f18e855a51912add1e8b26328a62d3d with metadata #<struct Fluent::Plugin::Buffer::Metadata timekey=1672969300, tag=\"example.log\", variables=nil> to s3://example_bucket/log/year=2023/month=01/day=06/5f18e855a51912add1e8b26328a62d3d.gz",
}
続いて上記の抽出したログに対し、元のタグ (ここでは example.log) を含む部分を正規表現により取得し、後述する KDS のパーティションキーとして利用するため追加します。
<filter fluent.debug>
@type record_transformer
enable_ruby
<record>
# 元のタグを正規表現で抽出しkinesisのpartition keyに利用
partition_key ${record["message"].match(/tag=.+,/)[0].slice(0..-2)}
</record>
</filter>
下記のようにparition_keyが新たに追加されます。
{
"time": "2023-01-06",
"level": "debug",
"message": ...
"partition_key": "tag=\"example.log\""
}
fluent.debugタグのレコードを KDS へ送信しないようにするため下記により除外します。
<filter fluent.debug>
@type grep
<exclude>
key partition_key
pattern /fluent.debug/
</exclude>
</filter>
KDS
先ほど抽出した元のタグをパーティションキーに設定し KDS へ送信します。これにより同じタグのレコードは毎回同じシャードに送信され順序性が担保されます (KDS はシャード内でのみ順序を保証します)。
<match fluent.debug>
@type kinesis_streams
stream_name example_stream
partition_key partition_key
</match>
なお最終的に KDS へ送信されるデータは下記となります。この例の場合tag="example.log"が送信先のシャード決定に利用されます。Consumer 側ではmessageに含まれるオブジェクトキーを用いて本体データを取得できます。
{
"time": "2023-01-06",
"level": "debug",
"message": "out_s3: write chunk 5f18e855a51912add1e8b26328a62d3d with metadata #<struct Fluent::Plugin::Buffer::Metadata timekey=1672969300, tag=\"example.log\", variables=nil> to s3://example_bucket/log/year=2023/month=01/day=06/5f18e855a51912add1e8b26328a62d3d.gz",
"partition_key": "tag=\"example.log\""
}
以上の内容を一つにまとめたものが下記となります。
<system>
log_level debug
<log>
format json
time_format %Y-%m-%d
</log>
</system>
<match example.log>
@type s3
s3_bucket example_bucket
s3_object_key_format ${tag[1]}/%{time_slice}/${chunk_id}.%{file_extension}
store_as gzip
time_slice_format year=%Y/month=%m/day=%d
<format>
@type json
</format>
<buffer time,tag>
timekey 10s
</buffer>
</match>
<label @FLUENT_LOG>
<filter fluent.debug>
@type grep
<regexp>
key message
pattern /out_s3: write chunk/
</regexp>
</filter>
<filter fluent.debug>
@type record_transformer
enable_ruby
<record>
partition_key ${record["message"].match(/tag=.+,/)[0]}
</record>
</filter>
<filter fluent.debug>
@type grep
<exclude>
key partition_key
pattern /fluent.debug/
</exclude>
</filter>
<match fluent.debug>
@type kinesis_streams
stream_name example_stream
partition_key partition_key
<buffer time>
timekey 10s
</buffer>
</match>
</label>
まとめ
本記事では Fluentd から Kinesis Data Streams へ大きなサイズのレコードを取り扱う具体的な方法例についてご紹介しました。ご参考にいただければ幸いです。